Machine Learning für jedes Budget
Wie man "KI" auch für kleine Unternehmen und dem Mittelstand nutzbar machen kann.
von Dr. Tomás Silveira Salles
Lesedauer ca. 13 Minuten
Über den Autor
Dr. Tomás Silveira Salles
... schreibt über aktuelle IT-Trends und versucht auch für den interessierten Laien ein bißchen Licht ins Dunkel jenseits von Hype und Buzzwords zu bringen..
Technologie, Handel, Wissenschaft, Medizin, Kunst und Schnurrbärte für Selfies. Maschinelles Lernen wird Teil von fast jedem Aspekt unseres Lebens und jeder möchte davon profitieren. Aber wenn Sie ein mittelständisches Unternehmen leiten und auf diesen Zug aufspringen möchten, ohne die Zeit oder Ressourcen Ihrer Mitstreiter zur Verfügung zu haben, werden Sie schließlich auf eine gewaltige Herausforderung stoßen: Sammeln von Daten.
Die Implementierung eines neuronalen Netzwerks ist heute einfacher als je zuvor genau so wie das Testen, Optimieren der Genauigkeit und die Ausgabe statistischer Daten, um die Ergebnisse zu rechtfertigen, wenn über Investitionen nachdenkt. Tools wie Google TensorFlow kümmern sich um die Mathematik und Sie brauchen nur noch einige wenige High-Level-Objekte und Anweisungen zu verwenden und Ihre Lieblings-Programmiersprache wird sicher auch schon unterstützt.
Um das Netzwerk zu trainieren, benötigen Sie jedoch "beschriftete" Daten, die aus Beispielen für die Dinge bestehen, die das Programm analysieren soll, gepaart mit den Informationen, die es idealerweise daraus schlußfolgern soll.
Wir alle wissen: "the internet is made of cats". Eine beispielhafte Anwendung könnte also dazu dienen, Bilder zu analysieren und erkennen, ob es sich um Katzenbilder handelt oder nicht. Dazu müssen aber erstmal zahllose Bilder von Katzen mit dem Vermerk "Katze" und jede Menge weitere Bilder von Hunden und Autos und Blumen usw. mit "keine Katze" zusammengetragen werden.
Dieser Artikel ist ein kurzer "Leitfaden zum Daten-Sammeln", in dem wir zeigen wollen, dass Machine Learning wirklich etwas für alle ist. Kleine Unternehmen müssen nur härter - aber vor allem klüger - arbeiten, um die wahrscheinlich bescheidene Datenmenge zu kompensieren, die sie zusammentragen können. Und der Teil mit dem "klüger" ist der, auf den wir hier unser Augenmerk richten wollen.
In diesem Artikel zeigen wir verschiedene Methoden, die im Machine Learning verwendet werden, erklären, wann und wo sie am effektivsten angewendet werden können und wie sie sich in ihrem Datenhunger unterscheiden.
Zu viel Info und zu wenig Zeit?
Zur Zusammenfassung!
Die schiere Menge an Daten ist normalerweise schon ein Problem. Abhängig von der Schwierigkeit der Aufgabe und der Genauigkeit, die Ihr Anwendungsfall verlangt, benötigen Sie möglicherweise Tausende von Beispielen, oder sogar Zehntausende oder Hunderttausende. Es könnte für ein kleines Unternehmen bereits ein unmögliches Unterfangen sein, allein die Rohdaten zusammenzutragen. Sie dann auch noch zu beschriften, ist der zweite Teil der Herausforderung.
Wenn Sie Glück haben, ist das Beschriften eines jeden einzelnen Beispiels eine leichte Sache und Sie können andere Menschen dazu bringen, Ihnen zu helfen. Googles reCAPTCHA ist ein Beispiel für ein massives Online-Outsourcing zum Beschriften von Daten, teilweise als Trainingsdaten für Machine Learning, aber auch für Digitalisierung von Büchern und mehr.
Wenn jedoch die Analyse Ihrer Daten Fachwissen erfordert (z. B. Klassifizieren von Bildern von Pilzen in die Kategorien "schmackhaft", "giftig" und "nicht im Büro essen"), kostet die Beschriftung nicht nur mehr Geld, sondern auch mehr Zeit als Sie sich leisten können. Es muss nämlich von einer kleinen Gruppe von Personen erledigt werden und die Analyse jedes einzelnen Beispiels braucht länger. Außerdem muss diese ggf. von mehr als einem Experten aus Sicherheitsgründen überprüft werden.
Wenn wir über beschriftete Daten sprechen, konzentrieren wir uns auf einen Bereich von Machine Learining, der als Supervised Learning, also "überwachtes Lernen", bezeichnet wird. Er wird "überwacht" genannt, weil (während des Trainings) die vorhandene Beschriftung jedes Beispiels der Maschine genau sagt, was die korrekte Ausgabe ist. Dies ist aber nicht die einzige Art des Machine Learnings und in vielen Fällen nicht die am besten Geeignete.
Bei unüberwachtem Lernen geht es darum, gängige Muster in den Daten zu finden, ohne diese vorher zu kennen.
Angenommen, Sie finden eine riesige Bibliothek auf dem Mars mit Tausenden von Büchern, die in einer altertümlichen Fremdsprache geschrieben sind und ein altertümliches Alien-Alphabet verwenden. Ihre Aufgabe besteht darin, diese Bücher zu digitalisieren, herauszufinden, welche Buchstaben in diesem Alphabet existieren, welche Wörter und Ausdrücke vorkommen usw. Da Sie das Alphabet am Anfang nicht kennen, gibt es keine Möglichkeit, die Daten für die einzelnen Buchstaben zu beschriften. Selbst wenn Sie durch hundert Bücher gehen und die Buchstaben manuell klassifizieren, könnte das Buch Nummer 7498 einen neuen Buchstaben haben, auf den Sie noch nicht gestoßen sind. Und was noch wichtiger ist: Eigentlich haben die Buchstaben keine Namen am Anfang und es interessiert Sie auch nicht wirklich, welche Namen ihnen zugewiesen werden. Man könnte sie "erster Buchstabe", "zweiter Buchstabe" usw. nennen, aber das ist Ihnen erstmal egal.
Diese Aufgabe ist ein Fall für das "Unsupervised Learning", das unüberwachte Lernen.
Beim unüberwachtem Lernen geht es darum, gängige Muster in den Daten zu finden, ohne diese vorher zu kennen. Sie können eine Maschine dazu bringen alle Alien-Bücher zu scannen und ein einfaches Programm darüber laufen lassen, um die Glyphen basierend auf dem umliegenden Leerraum zu isolieren und so einen riesigen Satz von Datenpunkten (aber keine Bezeichner) zu erstellen. Unter Verwendung von Unsupervised Learning könnte ein Computer dann die Glyphen (die "Bilder" der Buchstaben) in Gruppen organisieren, die den gleichen Mustern zu folgen scheinen und daher wahrscheinlich den gleichen Buchstaben darstellen. Am Ende entspricht jede resultierende Gruppe einem Buchstaben im Alien-Alphabet und Sie können die Buchstaben benennen, wie Sie möchten. Dadurch werden die vorhandenen Daten automatisch beschriftet (da sie bereits in die richtigen Gruppen unterteilt sind) und es wird leicht, die Bücher als Textdateien zu digitalisieren und Listen aller vorkommenden Wörter, häufiger Wortfolgen usw. zu erstellen.
Beim verstärkenden Lernen geht es darum, die Maschine ihre eigenen Annahmen (Lösungen) für jede Eingabe erarbeiten zu lassen und dann zu bewerten, wie gut jede Schätzung war.
Ein anderes Beispiel: Sie beschließen, eine riesige Bibliothek auf dem Mars zu bauen, aber da Sie nur ein paar Astronauten mitgebracht haben, müssen Sie Drohnen verwenden, um die Marsziegel zu schleppen. Leider sind die Marsmenschen nicht glücklich über das Projekt und werfen immer wieder Steine auf die vorbeifliegenden Drohnen. Sie brauchen einen Computer, der jede einzelne Drohne steuert und nicht abstürzen lässt. Jede Drohne ist dafür mit vielen Sensoren bestückt (ein Gyroskop, ein Beschleunigungsmesser, Kameras, Windsensoren, ein Höhensensor, ein Radar usw.).
Machine Learning kann hier helfen, aber es gibt keine Möglichkeit, ausreichend beschriftete Daten zu produzieren. In diesem Fall bestünde ein Datenpunkt aus einem Satz von Werten mehrerer Sensoren einer Drohne, und eine Beschriftung wäre ein Befehl wie "Erhöhen des Schubs auf den Propeller 3 um 42%". Die möglichen Sensorenwerte sind viel zu viele und Sie wissen nicht, wie man einen einzelnen Datenpunkt beschriften sollte, weil komplexe Physik im Spiel ist. Für diesen Fall ist "Reinforcement Learning" (Verstärkendes Lernen) gedacht.
Beim verstärkenden Lernen geht es darum, die Maschine ihre eigenen Lösungen für jede Eingabe erarbeiten zu lassen und dann nachher zu bewerten, wie gut jede Schätzung war.
Dabei gibt es keine "einzig richtige" Lösung. Wenn Sie zum Beispiel nicht möchten, dass Ihre Drohnen abstürzen, sollten Sie vermeiden, dass Sie dem Boden zu nahe kommen. Also, anstatt dem Computer genau zu sagen, was mit jedem Propeller zu tun ist, lassen Sie ihn einfach raten, und prüfen dann, ob die Drohne dem Boden näher kommt. Wenn dies der Fall ist, war die gewählte Reaktion eine schlechte Idee und der Computer sollte daraus lernen, damit das nicht wieder passiert. Diese "Bewertung" von Lösungen kann automatisch durchgeführt werden (beispiesweise unter Verwendung des Höhensensors der Drohne), so dass während der Trainingsphase keine Eingabe von Menschenhand notwendig ist.
Aber selbst wenn das alles nicht hilft und Sie wirklich beschriftete Daten benötigen, um Ihr Problem zu lösen: Es gibt noch Hoffnung! Im Folgenden zeigen wir drei wichtige Methoden, die als Abwandlungen des überwachten Lernens zu betrachten sind und dabei helfen, bessere Ergebnisse zu erzielen, selbst wenn Daten rar sind.
Beim teilüberwachten Lernen kann ein großer Satz nicht beschrifteter Daten verwendet werden, um die Genauigkeit der Maschine zu verbessern.
Sie haben sich entschieden, Karate zu lernen und für einige Kurse angemeldet. Während des Unterrichts sagt Ihnen Ihr Meister, wie man kickt und schlägt und blockt und springt. Er zeigt Ihnen die Bewegungen, führt Ihren Körper während Sie es versuchen und gibt Feedback nach jedem Versuch. Aber weil Sie schnell lernen wollen, bleiben Sie nach dem Unterricht noch da, üben weiter vor dem Spiegel und korrigieren sich basierend auf dem, was der Meister Ihnen bisher beigebracht hat.
Der Kurs dauert immer nur eine Stunde, aber danach können Sie mehrere Stunden trainieren, bevor der Hausmeister Sie rauswirft.
Das Training mit der Hilfe des Masters entspricht der Verwendung von beschrifteten Daten (passend als "überwachtes" Training bezeichnet), während das eigenständige Training der Verwendung von unbeschrifteten Daten entspricht (passend als "unüberwachtes" Training bezeichnet). Machine-Learning Algorithmen können einen ähnlichen "gemischten" Ansatz verwenden, der als teilüberwachtes Lernen bezeichnet wird.
Beim teilüberwachten Lernen kann ein kleiner Satz beschrifteter Daten für das anfängliche Training verwendet werden, und ein viel größerer Satz unbeschrifteter Daten, um die Genauigkeit oder das Vertrauen der Maschine zu verbessern.
Dies kann in Fällen nützlich sein, in denen das Beschriften von Daten schwierig ist, aber trotzdem reichlich Daten vorhanden sind. Ein bekanntes Beispiel für eine erfolgreiche Anwendung von teilüberwachtem Lernen ist die Spracherkennung. Beschriftete Daten bestehen in diesem Fall aus Audioaufzeichnungen von Silben, einzelnen Wörtern oder kurzen Phrasen, zusammen mit Text-Transkripten. Natürlich können große Unternehmen, die an Spracherkennung interessiert sind, viel Geld und viel Zeit investieren und große Mengen markierter Daten produzieren, aber nicht annähernd so groß wie die Menge existierender, öffentlicher, unbeschrifteter Daten, wie zum Beispiel die Audiotracks aller Filme, TV Shows und Youtube Videos. Die anfängliche überwachte Phase mit einem unüberwachten Training zu ergänzen, ist einfach und billig und kann sehr hilfreich sein.
Natürlich kann auch unüberwachtes Training für eine Aufgabe, die eine spezifische gewünschte Ausgabe für jeden Datenpunkt aufweist, gefährlich sein. Im Karate-Beispiel haben Sie möglicherweise Ihren Meister bei einer bestimmten Übung missverstanden. Wenn Sie diese Übung einige Stunden nach dem Unterricht falsch machen, wird es in der nächsten Lektion schwieriger, den Fehler zu beheben, als wenn Sie gar nicht erst selbst trainiert hätten. Ähnliche Probleme können beim teilüberwachten maschinellen Lernen auftreten. Es ist daher wichtig zu prüfen, ob die nicht markierten Daten hilfreich sind oder nicht.
Beim aktiven Lernen wählt oder erstellt das Gerät selbst sorgfältig Datenpunkte, die Sie beschriften können.
Janes Mathe Prüfung ist nächste Woche. Heute hatte sie ihren letzten Unterricht vor der Prüfung und ihr Lehrer hat gesagt: "Morgen Nachmittag bin ich für eine Stunde in meinem Büro, um Fragen zu beantworten." Jane ist fit in der Trigonometrie und sehr gut beim Lösen von quadratischen Gleichungen, aber die Matrixmultiplikation ist immer noch ein Problem.
Es ist offensichtlich, was sie während der Fragestunde tun sollte: Fragen zur Matrixmultiplikation stellen. Sie weiß, was ihre größte Schwäche ist und sollte sich während der begrenzten Zeit, in der sie Fragen stellen darf darauf konzentrieren. Warum sollten Maschinen also anders lernen?
In Bezug auf maschinelles Lernen wird dieser Ansatz als aktives Lernen bezeichnet. Grundsätzlich kann die Maschine nach einem überwachten Lernen mit einer kleinen Menge markierter Daten ihre Schwächen analysieren und Sie bitten, einige (sorgfältig ausgewählte) Datenpunkte zu beschriften, die ihr dabei helfen, so viel wie möglich zu lernen.
Die neuen Datenpunkte, die beschriftet werden, können aus einer großen Menge unbeschrifteter Daten stammen, die Sie von Anfang an bereitstellen, oder von einer tatsächlichen Anwendung des Programms (d.h., jemand benutzt tatsächlich die trainierte Maschine in einem realen Fall und die Eingabe fungiert als ein unmarkierter Datenpunkt), oder sie könnten sogar von der Maschine selbst erzeugt werden, als ob Jane zwei Matrizen niedergeschrieben hätte und ihren Lehrer gebeten hätte, ihr zu zeigen, wie man sie multipliziert.
Es gibt zusätzlich mehrere Kriterien, anhand derer die Maschine entscheiden kann, welche unmarkierten Datenpunkte "am hilfreichsten" sind. Die gängisten sind: Verringerung der Fehlerrate, Verringerung der Unsicherheit und Verringerung der Lösungsmenge.
Das erste - Verringerung der Fehlerrate - ist als allgemeines Konzept ziemlich offensichtlich (auch wenn die genaue Bedeutung der "Fehlerrate" sehr kompliziert sein kann).
Die Verringerung der Unsicherheit ist weniger offensichtlich. In den meisten gängigen maschinellen Lernalgorithmen mit diskreter Ausgabe - wie beispielsweise dem Klassifizieren von Bildern als "Katze" oder "keine Katze" - berechnet der Algorithmus zuerst einen Wert, der dazwischen liegen kann, zum Beispiel "45% Katze und 55% keine Katze "und gibt dann die nächste gültige Ausgabe zurück (in diesem Fall "keine Katze"). Die Tatsache, dass 45% und 55% so nahe sind, zeigt jedoch, dass die Maschine hinsichtlich der Ausgabe etwas unsicher ist, und in solchen Fällen ist es am wahrscheinlichsten, dass die Maschine falsch liegt. Die Verringerung der Unsicherheit bedeutet, dass die Maschine weiter trainiert wird, so dass dieser Zwischenwert die möglichen Ausgaben klarer trennt, wie beispielsweise "5% Katze und 95% keine Katze".
Die Reduktion der Lösungsmenge ist, allerdings, das am wenigsten intuitive Kriterium.
Angenommen, Sie sind ein Polizist, der einen Mordfall löst. Die Kollegen haben zehn Verdächtige in der Nähe des Tatortes festgenommen und Sie stellen diese nun dem einzigen Zeugen gegenüber, der aber leider das Gesicht des Mörders nicht gesehen hat. Mit Ihren hervorragenden Beobachtungsfähigkeiten bemerken Sie, dass 5 der Verdächtigen Menschen sind und die anderen 5 Marsmenschen. Wenn Sie nun den Zeugen fragen, ob die Haut des Angreifers grün war, oder ob der Angreifer Antennen auf seinem Kopf hatte oder nicht, können Sie die Anzahl der Verdächtigen schnell auf 5 reduzieren, egal wie die Antwort lautet.
Im Hinblick auf maschinelles Lernen entsprechen die Informationen, die Sie über den Mörder haben, den beschrifteten Daten. Die Fragen, die Sie nun dazu stellen könnten, entsprechen den unbeschrifteten Daten und die Verdächtigen entsprechen den möglichen Modellen (die Arten auf die die Maschine ihre Parameter einstellen könnte), die zu den derzeit bekannten Informationen passen. D.h. die Modellen, die zumindest auf die aktuellen Trainingsdaten die richtigen Antworten erhalten.
Wenn Sie aufgefordert werden, einen gut gewählten Datenpunkt zu beschriften (was dem Polizisten entspricht, der eine neue Frage stellt), kann die Maschine die Möglichkeiten für ihre Parameter eingrenzen und sich hoffentlich dem "richtigen Modell" annähern.
Das Transfer-Lernen ermöglicht es, Maschinen mit einer kleinen, für Ihre Anwendung spezifischen Datenmenge, zusammen mit einer großen, für eine ähnliche Anwendung gesammelten Datenmenge zu trainieren.
Am selben Tag, an dem Sie sich für den Karate-Kurs angemeldet haben, hat sich auch dieser arrogante Typ namens Bruce angemeldet. Der Unterschied zwischen Ihnen und Bruce ist, abgesehen von seiner Arroganz, dass er ein Kung-Fu-Schwarzgurt ist. Bruce ist super fit, flexibel, stark und schnell, hat tolle Reflexe und weiß bereits, wie man kickt und schlägt und blockiert und springt, nur eben in einer anderen Kampfsportart. Selbst wenn es Ihnen schwer fällt zuzugeben, wird Bruce realistischerweise wahrscheinlich viel schneller Karate lernen als Sie. Was er macht, heißt Transfer-Lernen.
Beim Transfer-Lernen wird die Maschine erstmal nicht für die Zielanwendung trainiert, sondern für eine ähnliche, für die es reichlich markierte Daten gibt. Danach wird sie ein zweites Mal trainiert, jetzt mit den Daten für die endgültige Anwendung. Selbst wenn die Datenmenge in der zweite Phase kleiner ist, kann sie trotzdem für sehr hohe Genauigkeit ausreichen, weil die Parameter nach der ersten Phase schon nah an ihren optimalen Werten sind.
In diesem Artikel, der im Februar im Cell Journal veröffentlicht wurde, trainierte eine Gruppe von Forschern eine Maschine zur Klassifizierung von "Makuladegeneration und diabetischer Retinopathie mittels retinaler optischer Kohärenztomographie". Mit anderen Worten, sie trainierten eine Maschine, um (eine bestimmte Art von) Bildern von Netzhäuten zu sehen und herauszufinden, ob auf den Bildern eine von einigen "gewöhnlichen, behandelbaren, zur Erblindung führenden Netzhauterkrankungen" zu sehen war, die so früh wie möglich diagnostiziert werden müssen.
Anstatt von vorne anzufangen, nahmen sie ihre Anfangsparameter aus einem neuronalen Netzwerk, das bereits an mehreren zehn Millionen beschrifteter Datenpunkte von ImageNet trainiert wurde, einer Datenbank mit Bildern aller möglichen Dinge, die mit den Namen der Objekte beschriftet sind. Dann passten sie das Netzwerk an, um Bilder in ihre eigenen Kategorien von Interesse zu klassifizieren (3 verschiedene Netzhauterkrankungen und 1 Kategorie für "normal / keine Krankheit") und trainierten es mit nur etwa 100.000 beschrifteten Bildern von Netzhäuten. Nach 2 Stunden Training hatte die Maschine bereits eine ähnliche Genauigkeit erreicht wie die 6 Experten, mit denen sie verglichen wurde. Um noch weiter zu gehen und die Nützlichkeit des Transfer-Lernens für solche Anwendungen zu beweisen, nahmen sie das ursprüngliche neuronale Netzwerk (trainiert nur anhand der ImageNet-Datenpunkten) und trainierten es erneut, aber diesmal mit nur 1.000 Netzhautbildern aus jeder ihrer vier Kategorien. Das Training dauerte nur etwa 30 Minuten und die Ergebnisse - wenn auch etwas ungenauer als zuvor - lagen immer noch ziemlich nahe bei der Genauigkeit der menschlichen Experten und produzierte weniger falsche positive Ergebnisse als eine/einer von ihnen.
Obwohl es unwahrscheinlich ist, dass KI bald menschliche Ärzte ersetzen wird, könnte es sicherlich ein hilfreicher Verbündeter werden, zum Beispiel um den Vor-Screening-Prozess zu beschleunigen, offensichtliche Negative zu beseitigen, offensichtliche Positive schnell zu erkennen und so weiter. Und wegen des Levels von Fachwissen, das benötigt wird, um Datenpunkte in jedem Bereich der Medizin zu Beschriften, wäre dies ohne Transfer-Lernen fast unmöglich zu erreichen.
Okay, das war ein langer Artikel mit vielen Definitionen, und eine Zusammenfassung ist jetzt wahrscheinlich sehr willkommen:
Wir haben drei Lernstile skizziert, die sich größtenteils gegenseitig ausschließen: überwachtes, unüberwachtes und verstärkendes Lernen. Danach haben wir noch drei Varianten des überwachten Lernens beschrieben, die getrennt oder kombiniert angewendet werden können: teilüberwachtes, aktives und Transfer-Lernen.
Hier sind nochmal alle sechs Methoden, kurz zusammengefasst:
➕➖ Unüberwachtes Lernen
Die Trainingsdaten sind hier unbeschriftet. Unüberwachtes Lernen wird oft für "Clustering"-Probleme verwendet, das heißt für das Gruppieren von Dingen, die gemeinsame Muster teilen, ohne vorher zu definieren, welche Gruppen existieren sollten. Das entsprechende Beispiel ist die Klassifizierung der Glyphen im unbekannten Alien-Alphabet.
➕➖ Verstärkendes Lernen
Die Trainingsdaten sind unbeschriftet, aber wenn wir der Maschine einen Eingabedatenpunkt geben und diese dann rät, was die Ausgabe sein könnte, können wir die Qualität der Schätzung leicht auswerten. Das korrespondierende Beispiel ist die Kontrolle der Drohnen, die auf dem Mars herumfliegen, und die Beurteilung der Qualität eines Manövers durch den Höhenwechsel (um nicht mit dem Terrain zu kollidieren).
➕➖ Überwachtes Lernen
Die Datenpunkte sind schon vorab so beschriftet, wie die späteren Ergebnisse von der Maschine erwartet werden. Überwachtes Lernen kann verwendet werden, um Dinge in Gruppen zu organisieren, wenn die Gruppen bereits bekannt sind, wie zum Beispiel die Einteilung von Bildern in die Kategorien "Katze" und "keine Katze". Eine weitere häufige Anwendung von überwachtem Lernen ist, wenn die erwartete Ausgabe ein kontinuierlicher Wert ist. Auf der Grundlage der Verkaufsdaten für ein bestimmtes Produkt in den letzten 10 Jahren soll beispielsweise geschätzt werden, wie viel davon das Unternehmen im nächsten Monat produzieren sollte, um den Gewinn zu maximieren.
➕➖ Teilüberwachtes Lernen
Hier wird unüberwachtes und überwachtes Lernen kombiniert. Ideal, wenn wenige beschriftete Daten verfügbar sind, aber viele unbeschriftete. Das Beispiel, das hierzu passt, ist der Karateunterricht bei einem Lehrer und das anschließende Training nach dem Unterricht.
➕➖ Aktives Lernen
Dies ist eine Ergänzung zum grundlegenden überwachten Lernen, bei dem die Maschine unbeschriftete Datenpunkte sorgfältig auswählen oder sorgfältig entwerfen und Sie dann auffordern kann, diese zu beschriften, damit sie schneller und besser lernen kann, indem sie sich nur auf ihre eigenen Schwächen konzentriert. Das entsprechende Beispiel ist die Fragestunde mit dem Mathematiklehrer vor der Prüfung.
➕➖ Transfer-Lernen
Eine weitere Ergänzung zum überwachten Lernen. Wenn zu einem ähnlichen Problem bereits viele beschriftete Daten vorliegen, kann eine Maschine, die für dieses ähnliche Problem trainiert wurde, für Ihr spezifisches Problem angepasst und neu trainiert werden, damit sie nicht von vorne anfangen muss. Das Beispiel, an das man denken sollte, ist der fähige Kung-Fu-Kämpfer, der sich entscheidet, Karate zu lernen.
Zum Schluß noch ein einfaches Diagramm, das der Entscheidung für die geeignete Lernmethode nochmal grafisch nachgeht:
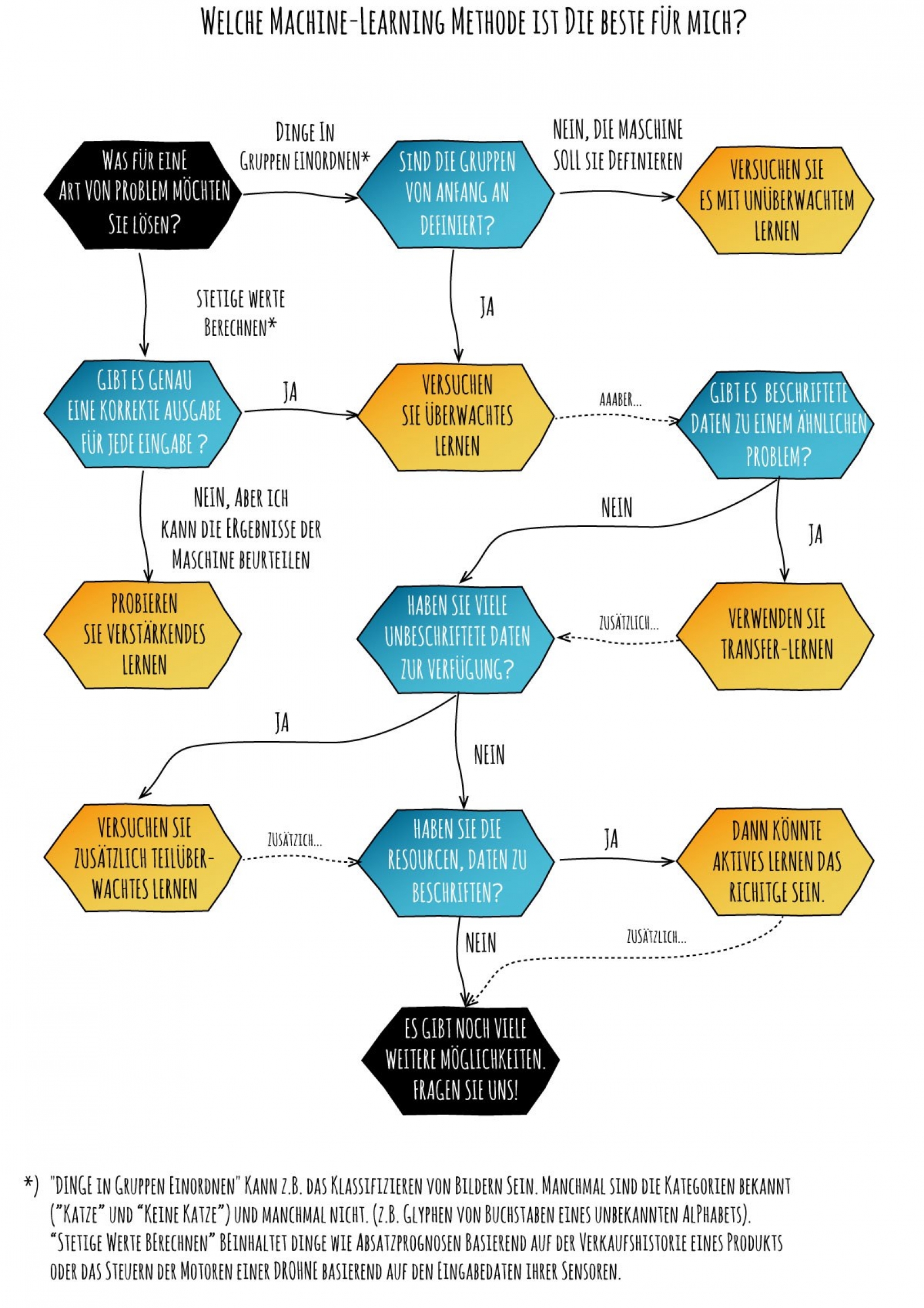
Flussdiagramm: Welche Machine-Learning Methode ist für mich am besten geeignet?
Fragen zu Machine Learning und AI? Schreiben Sie uns!
Die Nachricht konnte nicht gesendet werden:
Vielen Dank für Ihre Nachricht!
 EN
EN